
Начиная с версии 7.0, EhP2 в ABAP была введена новая концепция обработки внутренних (внешних) данных — потоковая обработка данных.
Поток – ссылка на последовательный набор записей данных, чей конец может быть не известен. Потоки разделяются по виду: потоки данных и фильтрующие потоки.
Фильтрующие потоки в настоящее время не реализованы и не рассматриваются в данной статье.
Потоки данных – такие потоки, которые напрямую соединены как читающий поток к источнику данных или как записывающий поток к приемнику данных.
Читающий поток (входящий поток) – любой поток данных, присоединенный к источнику данных. В качестве читающего потока может выступать фильтрующий поток, присоединенный к читающему потоку. Направление читающего потока всегда исходит от источника данных (например, от поля таблицы базы данных к объекту представляющему поток), через читающий поток нельзя записывать данные.
Источник данных – хранилище, из которого происходит получение данных читающим потоком. Источником может быть LOB поле в базе данных, файл, строка или внутренняя таблица. В настоящее время чтение доступно для полей из таблиц баз данных (LOB поля), строк и внутренних таблиц.
LOB – Large object, может быть двух видов: BLOB или CLOB. BLOB – Binary large object. Поле в таблице базы данных с типом данных RAWSTRING. CLOB – Character large object. Поле в таблице базы данных с типом данных STRING.
Записывающий поток (исходящий поток) – любой поток данных, присоединенный к приемнику данных. В качестве записывающего потока может выступать фильтрующий поток, присоединенный к записывающему потоку. Направление записывающего потока всегда направлено к приемнику данных, т.о. записывающий поток используется только для записи.
Приемник данных – хранилище, в котором записывающий поток сохраняет свои данные. В качестве приемника может быть LOB поле в базе данных, файл, строка или внутренняя таблица. В настоящее время запись реализована для полей таблиц БД, строк и внутренних таблиц.
Потоки данных всегда имеют одно направление – на чтение или на запись.
Кроме направления потоки данных могут иметь следующие типы: бинарный поток, символьный поток. Бинарный поток содержит данные с байтовым типом данных (x, xstring), родовой тип xsequence (для полей таблиц RAWSTRING). Символьный поток содержит данные с символьным типом данных (с, string).
В ABAP, потоки представлены в виде инстанций специального набора классов, передача (получение) данных осуществляется с помощью вызова соответствующих методов.
Свойства потоков:
- Вид потока – поток данных или фильтрующий поток
- Направление потока – на чтение или на запись
- Тип потока – символьный поток или бинарный поток.
Классы и интерфейсы, реализующие в ABAP концепцию потоков, лежат в пакете SABP_STREAMS_AND_LOCATORS. Следующая диаграмма демонстрирует основные классы и интерфейсы:
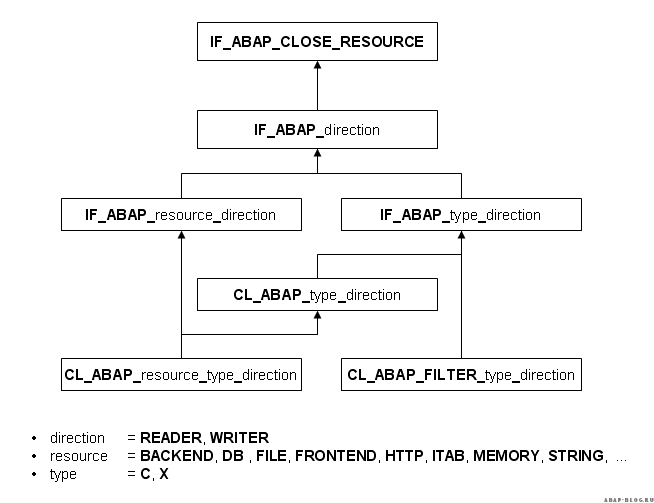
Классы для работы с потоками данных начинаются с «CL_ABAP_» и содержат следующие идентификаторы:
- Resource – источник для чтения или приемник для записи, в настоящее время поддерживаются: строки (STRING), LOB поля в БД (DB), внутренние таблицы (ITAB).
- Type – тип потока, бинарный (X) и строковый (C).
- Direction – направление потока, запись (WRITER) и чтение (READER).
Имена классов для фильтрующих потоков начинаются с «CL_ABAP_FILTER_» и именуются по тем же правилам. В настоящее время фильтрующие потоки не реализованы (Версия 7.02-7.31).
Основные методы, используемые для работы с потоками, описаны в интерфейсах и суперклассах как методы ядра (для просмотра можно воспользоваться программой RSKMETH), следовательно, их реализация обеспечивается средой выполнения ABAP. Основные методы при работе с потоками:
- DATA_AVAILABLE возвращает X если еще есть несчитанные данные.
- IS_X_READER возвращает X если является бинарным потоком.
- READ возвращает строку с заданным числом байтов или символов из потока.
- SKIP пропускает заданное количество байт или символов в потоке.
- WRITE запись данных потока в приемник.
- CLOSE закрывает поток (после чего читать или писать уже нельзя).
- IS_CLOSED возвращает X если поток закрыт.
- SET_MARK установить метку, к которой можно будет возвратиться позже.
- IS_MARK_SUPPORTED возвращает X если метки поддерживаются.
- RESET_TO_MARK возврат к метке.
Потоки к строкам
Для создания потоков, источником или приемником которых служат строки, используется следующий набор классов:
- CL_ABAP_STRING_C_READER
- CL_ABAP_STRING_C_WRITER
- CL_ABAP_STRING_X_READER
- CL_ABAP_STRING_X_WRITER
Данные классы являются потомками от абстрактных классов потоков внутренних данных — CL_ABAP_MEMORY_….
Пример программы с потоками для строк:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
DATA: string_writer TYPE REF TO cl_abap_string_c_writer, string_reader TYPE REF TO if_abap_c_reader. DATA snippet TYPE c LENGTH 1. CREATE OBJECT string_writer TYPE cl_abap_string_c_writer. DO 10 TIMES. string_writer->write( |{ sy-index - 1 }| ). ENDDO. string_writer->close( ). CREATE OBJECT string_reader TYPE cl_abap_string_c_reader EXPORTING str = string_writer->get_result_string( ). string_reader->skip( 3 ). WHILE string_reader->data_available( ) = 'X'. snippet = string_reader->read( 1 ). WRITE / snippet. ENDWHILE. string_reader->close( ). |
Потоки к внутренним таблицам
Для создания потоков, источником или приемником данных для которых служат внутренние таблицы, используется следующий набор классов:
- CL_ABAP_ITAB_C_READER
- CL_ABAP_ITAB_C_WRITER
- CL_ABAP_ITAB_X_READER
- CL_ABAP_ITAB_X_WRITER
Данные классы являются потомками от абстрактных классов потоков внутренних данных — CL_ABAP_MEMORY_….
Пример программы с потоками для внутренних таблиц:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
DATA: itab TYPE TABLE OF string, text TYPE string. DATA itab_reader TYPE REF TO if_abap_c_reader. APPEND `abc` TO itab. APPEND `def` TO itab. APPEND `ghi` TO itab. CREATE OBJECT itab_reader TYPE cl_abap_itab_c_reader EXPORTING itab = itab. WHILE itab_reader->data_available( ) = 'X'. text = itab_reader->read( 3 ). WRITE / text. ENDWHILE. itab_reader->close( ). |
Обработка LOB полей базы данных
Обработка LOB полей БД возможна с помощью потоков и локаторов, при этом есть следующие особенности их использования:
Локаторы:
- Связываются с LOB полями для чтения или записи через LOB дескрипторы, запись подразумевает копирование данных из других локаторов, возможности прямой записи из переменных ABAP программы через локатор в базу данных не существует (для этого используются записывающие потоки).
- Имеют доступ к вложенным последовательностям в LOB полях и их свойствам
- Позволяют копировать LOB поля, без переноса данных на сервер приложений
- За счёт обработки на стороне СУБД повышается и нагрузка на неё
- Для тех СУБД, где нет поддержки локаторов, она эмулируется на сервере приложений.
Потоки:
- Связываются, как и локаторы через LOB дескрипторы
- Данные LOB полей обрабатываются последовательно, используя методы потоков
- Не нагружают дополнительно СУБД.
Количество LOB дескрипторов на один DB LUW ограничено 1000. Открытых потоков может быть не более 16.
Пример копирования через локатор LOB поля, без переноса его содержимого на сервер приложений:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
DATA: locator TYPE REF TO cl_abap_db_c_locator. SELECT SINGLE longtext FROM lob_table INTO locator " <- Получить дескриптор (указатель) на LOB поле WHERE key = key1. UPDATE lob_table SET longtext = locator " <- Скопировать LOB поле с помощью локатора в другую таблицу WHERE key = key2. locator->close( ). " Необходимо позаботиться о закрытии локатора |
Пример считывания из БД с помощью потока:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
DATA: reader TYPE REF TO cl_abap_db_x_reader. SELECT SINGLE picture FROM demo_blob_table INTO reader " <- Получение LOB дескриптора для потока WHERE name = pic_name. ... WHILE reader->data_available( ) = 'X'. " <- Чтение данных из потока в файл TRANSFER reader->read( len ) TO pict_file. ENDWHILE. reader->close( ). |
Под LOB дескрипторами понимаются интерфейсы IF_ABAP_DB_LOB_HANDLE (*_BLOB_HANDLE, *_CLOB_HANDLE) и классы которые их внедряют. В примерах описанных выше используются классы, которые создаются и привязываются к LOB полю через дополнение INTO. Кроме того вместе классов можно использовать интерфейсы и дополнение CREATING в SQL операторе SELECT, для того чтобы создавать объекты в зависимости от типов полей, пример использования:
|
1 2 3 4 5 6 7 8 |
DATA: locator TYPE REF TO if_abap_db_lob_handle. SELECT SINGLE description FROM zhd_tasks INTO locator " <- Получить дескриптор (указатель) на LOB поле CREATING LOCATOR FOR COLUMNS description WHERE task = 761. |
В данном случае создается локатор для поля description. В зависимости от вида поля (BLOB или CLOB) создается экземпляр определенного класса (CL_ABAP_DB_C_LOCATOR или CL_ABAP_DB_X_LOCATOR). Данное дополнение можно использовать и динамически, по тем же правилам что и в других ABAP командах: CREATING… (текст команды создания). Ключевое слово LOCATOR (READER) определяет, какой объект мы создаем. Дополнение [ALL [OTHER] [BLOB|CLOB]] COLUMNS [blob1 blob2 … clob1 clob2 …] используется тогда, когда выбор происходит в структуру (таблицу).
В случае считывания структуры (таблицы), а не единичного поля, необходимо объявлять специальную LOB структуру. LOB структура представляет собой специальную рабочую область с теми же полями что и внутри таблицы БД, однако должен быть объявлен хотя бы один компонент с привязкой к LOB полю. Компонент представляет из себя ссылочную переменную, указывающую на LOB дескриптор (интерфейс или класс). Когда объявляется LOB структура, компоненты связанные с LOB полем, заменяются на соответствующий интерфейс (класс).
Объявление LOB структуры происходит следующим способом:
TYPES dtype TYPE dbtab lob_handle_type FOR lob_handle_columns
[lob_handle_type FOR lob_handle_columns
… ].
В dbtab должна быть указана база данных или ракурс из словаря. Поле lob_handle_type определяет тип LOB дескриптора:
… { READER|LOCATOR|{LOB HANDLE} }
| { WRITER|LOCATOR } …
READER определяет поля с типами:
- CL_ABAP_DB_X_READER для BLOB
- CL_ABAP_DB_C_READER для CLOB
WRITER определяет поля с типами:
- CL_ABAP_DB_X_WRITER для BLOB
- CL_ABAP_DB_C_WRITER для CLOB
LOCATOR определяет поля с типами:
- CL_ABAP_DB_X_LOCATOR для BLOB
- CL_ABAP_DB_C_LOCATOR для CLOB
LOB HANDLE определяет поля с типами:
- IF_ABAP_DB_BLOB_HANDLE для BLOB
- IF_ABAP_DB_CLOB_HANDLE для CLOB
Дополнения READER и WRITER нельзя указывать вместе. Дополнение WRITER так же не может быть использовано с дополнением LOB HANDLE.
Дополнение lob_handle_columns определяет, какие поля из таблицы БД мы будем использовать как LOB поля.
Синтаксис следующий:
… { COLUMNS blob1 blob2 … clob1 clob2 … }
| { ALL [OTHER] [BLOB|CLOB] COLUMNS } …
- COLUMNS – определяет индивидуальный перечень полей
- ALL OTHER BLOB|CLOB COLUMNS – включает остальные BLOB|CLOB поля не перечисленные при индивидуальном определении
- ALL BLOB|CLOB COLUMNS – включает все BLOB|CLOB поля таблицы
- ALL OTHER COLUMNS – включает все поля (BLOB и CLOB) не перечисленные в индивидуальном определении
- ALL COLUMNS – включает все CLOB и BLOB поля из таблицы
Программа, демонстрирующая объявление LOB структур:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 |
CLASS demo_lob_handles DEFINITION. PUBLIC SECTION. CLASS-METHODS main. TYPES: lob_handle_structure_1 TYPE demo_lob_table READER FOR COLUMNS clob1 blob1, lob_handle_structure_2 TYPE demo_lob_table LOB HANDLE FOR ALL COLUMNS, lob_handle_structure_3 TYPE demo_lob_table LOCATOR FOR ALL BLOB COLUMNS WRITER FOR ALL CLOB COLUMNS, lob_handle_structure_4 TYPE demo_lob_table READER FOR COLUMNS clob1 clob2 LOB HANDLE FOR ALL BLOB COLUMNS LOCATOR FOR ALL OTHER CLOB COLUMNS, lob_handle_structure_5 TYPE demo_lob_table READER FOR COLUMNS blob1 blob2 blob3 LOCATOR FOR COLUMNS clob1 clob2 clob3 LOB HANDLE FOR ALL OTHER COLUMNS, lob_handle_structure_6 TYPE demo_lob_table READER FOR COLUMNS blob1 LOCATOR FOR COLUMNS blob2 LOB HANDLE FOR COLUMNS blob3 LOB HANDLE FOR ALL CLOB COLUMNS. PRIVATE SECTION. CLASS-METHODS type_output IMPORTING struct TYPE string. ENDCLASS. CLASS demo_lob_handles IMPLEMENTATION. METHOD main. type_output( 'LOB_HANDLE_STRUCTURE_1' ). type_output( 'LOB_HANDLE_STRUCTURE_2' ). type_output( 'LOB_HANDLE_STRUCTURE_3' ). type_output( 'LOB_HANDLE_STRUCTURE_4' ). type_output( 'LOB_HANDLE_STRUCTURE_5' ). type_output( 'LOB_HANDLE_STRUCTURE_6' ). ENDMETHOD. METHOD type_output. DATA structdescr TYPE REF TO cl_abap_structdescr. DATA components TYPE abap_compdescr_tab. DATA component LIKE LINE OF components. DATA typedescr TYPE REF TO cl_abap_typedescr. DATA refdescr TYPE REF TO cl_abap_refdescr. DATA name TYPE string. structdescr ?= cl_abap_structdescr=>describe_by_name( struct ). components = structdescr->components. WRITE (47) struct COLOR 1 INTENSIFIED OFF. LOOP AT components INTO component. TRY. name = struct && '-' && component-name. refdescr ?= cl_abap_typedescr=>describe_by_name( name ). typedescr = refdescr->get_referenced_type( ). WRITE: /(6) component-name COLOR 1 INTENSIFIED OFF, (40) typedescr->absolute_name COLOR 2 INTENSIFIED OFF. CATCH cx_sy_move_cast_error. ENDTRY. ENDLOOP. SKIP. ENDMETHOD. ENDCLASS. START-OF-SELECTION. demo_lob_handles=>main( ). |
Кроме выше указанного способа LOB структуры могут быть объявлены в словаре или через BEGIN OF…END OF. Для более подробной информации рекомендую ознакомиться с документацией в ABAP (ссылки ниже).
Использование потоков в OpenSQL командах
Потоки могут быть следующих видов:
- CL_ABAP_DB_C_READER – для чтения данных из СLOB полей
- CL_ABAP_DB_X_READER – для чтения данных из BLOB полей
- CL_ABAP_DB_C_WRITER – для записи данных в СLOB поля
- CL_ABAP_DB_X_WRITER – для записи данных в BLOB поля
Основные методы при работе с потоками обработки LOB полей такие же, как и для других потоков (см. выше). В зависимости от направления потока различается и их процесс создания. Как было видно в примере выше, потоки для чтения LOB полей создаются автоматически через атрибут INTO оператора SELECT или через дополнение CREATING.
Создание записывающих потоков происходит с помощью операторов: INSERT, UPDATE, MODIFY. В зависимости от СУБД, обработка записывающих потоков может отличаться:
- В MaxDB или Oracle компоненты, которые не являются LOB дескрипторами, записываются сразу после выполнения команд обновления. Если обновление не может быть выполнено, в соответствующие поля (sy-subrc, sy-dbcnt) записываются коды ошибок и число обработанных записей, при этом записывающие потоки не создаются. Если обновление может быть выполнено, создаются записывающие потоки, при этом перенос данных из них происходит в момент, когда последний из них будет закрыт.
- В других СУБД компоненты, не являющиеся LOB дескрипторами, не переносятся в БД сразу же после операторов обновления. При этом записывающие потоки всегда создаются. Данные переносятся в БД только тогда, когда будет закрыт последний записывающий поток, открытый для этого оператора. Соответственно между выполнением оператора и закрытием последнего записывающего потока, статус операции является неопределенным. В поле sy-subrc после оператора будет записан код ошибки 2, а в sy-dbcnt значение -1. Перед закрытием потока необходимо получить указатель на объект класса CL_ABAP_SQL_CHANGING_STMNT, через интерфейс IF_ABAP_DB_WRITER используя метод GET_STATEMENT_HANDLE. С помощью метода GET_STATE данного класса можно получить статус OSQL операции, а с помощью метода GET_DB_COUNT количество обработанных записей. Кроме того с помощью данного объекта можно закрыть все открытые для записи потоки. Если операция не может быть выполнена (например, есть дубликаты в ключевых полях), система выдаст исключения CX_STREAM_IO_EXCEPTION или CX_CLOSE_RESOURCE_ERROR.
Записывающий поток будет открытым до тех пор, пока не будет выполнена отмена изменений через ROLLBACK, либо закрыт явным образом через метод CLOSE. В случае выполнения COMMIT WORK при открытых записывающих потоках, система вызовет динамическую ошибку — COMMIT_STREAM_ERROR.
Читающие потоки закрываются неявным способом в циклическом операторе SELECT после оператора ENDSELECT, а так же после окончания DB LUW.
Пример программы, заполняющей LOB поле через записывающий поток:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 |
PARAMETERS name TYPE c LENGTH 255 LOWER CASE DEFAULT '/SAP/PUBLIC/BC/ABAP/Sources/ABAP_Docu_Logo.gif'. CLASS demo DEFINITION. PUBLIC SECTION. CLASS-METHODS: class_constructor, main. PRIVATE SECTION. TYPES: pict_line(1022) TYPE x, pict_tab TYPE STANDARD TABLE OF pict_line . CLASS-DATA pict TYPE pict_tab. CLASS-METHODS get_pict_tab IMPORTING mime_url TYPE csequence EXPORTING pict_tab TYPE STANDARD TABLE. ENDCLASS. CLASS demo IMPLEMENTATION. METHOD main. DATA: xline TYPE xstring, " Объявляем LOB структуру с потоком на запись к полю picture wa TYPE demo_blob_table WRITER FOR COLUMNS picture, stmnt TYPE REF TO cl_abap_sql_changing_stmnt, subrc TYPE sy-subrc. TRY. wa-name = name. " Вставляем новую запись в таблицу, при этом создается записывающий поток INSERT demo_blob_table FROM wa. IF sy-subrc = 4. subrc = 4. ELSE. " Получаем ссылку на CL_ABAP_SQL_CHANGING_STMNT, " с помощью данного класса мы можем определить корректность обработки потока stmnt = wa-picture->get_statement_handle( ). " Записываем построчно считанные с MIME репозитария данные LOOP AT pict INTO xline. wa-picture->write( xline ). ENDLOOP. " Обязательно закрываем поток wa-picture->close( ). " Проверяем кол-во обработанных записей в таблице IF stmnt->get_db_count( ) <> 1. subrc = 4. ENDIF. ENDIF. CATCH cx_stream_io_exception cx_close_resource_error. subrc = 4. ENDTRY. IF subrc = 0. MESSAGE 'One line inserted, you can run DEMO_DB_READER now' TYPE 'S'. ELSE. MESSAGE 'Error during insertion' TYPE 'S' DISPLAY LIKE 'E'. ENDIF. ENDMETHOD. METHOD class_constructor. get_pict_tab( EXPORTING mime_url = name IMPORTING pict_tab = pict ). " Удалим запись с таким же именем. DELETE FROM demo_blob_table WHERE name = name. ENDMETHOD. METHOD get_pict_tab. DATA pict_wa TYPE xstring. DATA length TYPE i. DATA mime_api TYPE REF TO if_mr_api. mime_api = cl_mime_repository_api=>get_api( ). mime_api->get( EXPORTING i_url = mime_url IMPORTING e_content = pict_wa EXCEPTIONS OTHERS = 4 ). IF sy-subrc = 4. RETURN. ENDIF. CLEAR pict_tab. length = xstrlen( pict_wa ). WHILE length >= 1022. APPEND pict_wa(1022) TO pict_tab. SHIFT pict_wa BY 1022 PLACES LEFT IN BYTE MODE. length = xstrlen( pict_wa ). ENDWHILE. IF length > 0. APPEND pict_wa TO pict_tab. ENDIF. ENDMETHOD. ENDCLASS. START-OF-SELECTION. demo=>main( ). |
Программа, считывающая записанные выше данные:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 |
REPORT demo_db_reader. PARAMETERS name TYPE c LENGTH 255 LOWER CASE DEFAULT '/SAP/PUBLIC/BC/ABAP/Sources/ABAP_Docu_Logo.gif'. CLASS demo DEFINITION. PUBLIC SECTION. CLASS-METHODS main. PRIVATE SECTION. TYPES: pict_line(1022) TYPE x, pict_tab TYPE STANDARD TABLE OF pict_line . CLASS-DATA pict TYPE pict_tab. CLASS-METHODS show_picture. ENDCLASS. CLASS demo IMPLEMENTATION. METHOD main. DATA reader TYPE REF TO cl_abap_db_x_reader. SELECT SINGLE picture FROM demo_blob_table INTO reader WHERE name = name. IF sy-subrc <> 0. MESSAGE 'Nothing found, run DEMO_DB_WRITER first!' TYPE 'S' DISPLAY LIKE 'E'. RETURN. ENDIF. WHILE reader->data_available( ) = 'X'. APPEND reader->read( 1022 ) TO pict. ENDWHILE. reader->close( ). show_picture( ). ENDMETHOD. METHOD show_picture. DATA html_str TYPE string. DATA ext_data TYPE cl_abap_browser=>load_tab. DATA ext_line TYPE cl_abap_browser=>load_tab_line. html_str = '<html><body><img src="PICT.GIF" ></body></html>'. ext_line-name = 'PICT.GIF'. ext_line-type = 'image'. GET REFERENCE OF pict INTO ext_line-dref. APPEND ext_line TO ext_data. cl_abap_browser=>show_html( EXPORTING html_string = html_str format = cl_abap_browser=>landscape size = cl_abap_browser=>small data_table = ext_data check_html = ' ' ). ENDMETHOD. ENDCLASS. START-OF-SELECTION. demo=>main( ). |
Использование локаторов в OpenSQL
В настоящее время локаторы бывают двух видов:
- CL_ABAP_DB_C_LOCATOR – для CLOB полей
- CL_ABAP_DB_X_LOCATOR – для BLOB полей
Важные методы локаторов:
- GET_LENGTH – получает размер LOB поля подключенного к локатору
- FIND – поиск последовательности данных относительно смещения, возвращает позицию в LOB где встречается указанный для поиска шаблон. В Unicode системах размер символьного шаблона ограничен 1333 символами, в не Unicode системах 2666. Для байтового шаблона размер ограничен 2666 байтами.
- CLOSE – закрытие локатора и освобождение занятых им ресурсов
- IS_CLOSED – возвращает X если локатор закрыт
- GET_SUBSTRING – используется для CLOB полей, получает последовательность символов с указанным смещением и длинной
- GET_BYTES – тоже самое но для BLOB полей.
Локаторы могут создаваться только через оператор SELECT и его атрибут INTO, как это было показано выше. Создание локаторов не может быть инициировано при изменении данных таблиц. После создания, локаторы могут быть использованы для копирования LOB полей между записями таблицы.
Из-за нагрузки на СУБД закрытие локаторов должно происходить как можно скорее, причем в отличие от потоков, локаторы не закрываются автоматически при использовании циклического оператора SELECT, после команды ENDSELECT. Неявное закрытие локаторов происходит только после окончания LUW БД.
Программа копирующее LOB поле через локатор:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
REPORT demo_db_copy. PARAMETERS: source TYPE c LENGTH 255 LOWER CASE DEFAULT '/SAP/PUBLIC/BC/ABAP/Sources/ABAP_Docu_Logo.gif', target TYPE c LENGTH 255 LOWER CASE DEFAULT 'picture_copy'. CLASS demo DEFINITION. PUBLIC SECTION. CLASS-METHODS main. ENDCLASS. CLASS demo IMPLEMENTATION. METHOD main. DATA wa TYPE demo_blob_table LOCATOR FOR ALL COLUMNS. SELECT SINGLE picture FROM demo_blob_table INTO wa-picture WHERE name = source. IF sy-subrc <> 0. MESSAGE 'Nothing found, run DEMO_DB_WRITER first!' TYPE 'S' DISPLAY LIKE 'E'. RETURN. ENDIF. wa-name = target. INSERT demo_blob_table FROM wa. IF sy-subrc = 0. MESSAGE 'You can run DEMO_DB_READER with new name now' TYPE 'S'. ELSE. MESSAGE 'Target already exists' TYPE 'S' DISPLAY LIKE 'E'. ENDIF. wa-picture->close( ). ENDMETHOD. ENDCLASS. START-OF-SELECTION. demo=>main( ). |
Чтение данных, используя локатор:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
REPORT demo_db_locator. PARAMETERS: pattern TYPE c LENGTH 20 DEFAULT 'ABAP' LOWER CASE, language TYPE sy-langu DEFAULT sy-langu. CLASS demo DEFINITION. PUBLIC SECTION. CLASS-METHODS main. ENDCLASS. CLASS demo IMPLEMENTATION. METHOD main. DATA: otr_text_locator TYPE REF TO cl_abap_db_c_locator, search_pattern TYPE string, length TYPE i, hits TYPE i, avg TYPE p DECIMALS 2, msg TYPE string. search_pattern = pattern. TRY. SELECT text FROM sotr_textu INTO otr_text_locator WHERE langu = language. length = length + otr_text_locator->get_length( ). IF otr_text_locator->find( start_offset = 0 pattern = search_pattern ) <> -1. hits = hits + 1. ENDIF. otr_text_locator->close( ). ENDSELECT. CATCH cx_lob_sql_error. WRITE 'Exception in locator' COLOR = 6. RETURN. ENDTRY. avg = length / sy-dbcnt. msg = |Average length of strings in database table: { avg }|. WRITE: / msg. msg = |Occurrences of "{ pattern WIDTH = strlen( pattern ) }" | && |in strings of database table: { hits }|. WRITE: / msg. ENDMETHOD. ENDCLASS. START-OF-SELECTION. demo=>main( ). |
Справка на тему использования LOB и потоков: Потоки и локаторы в OSQL, Потоки в обработке внутренних данных. Видео обзор.
Добрый день!
Подскажите, пожалуйста, в каких случаях целесообразно использование потоков и локаторов в abap?
Заранее спасибо.
Здравствуйте, если эту концепцию расширят для работы с файлами будет весьма полезно. А пока их использование ограничивается редкими случаями, когда требуется хранить большие объекты данных в таблицах БД.