 Использование функционала поиска в HANA довольно обширная тема, которой посвящена отдельный гайд в документации.
Использование функционала поиска в HANA довольно обширная тема, которой посвящена отдельный гайд в документации.
В данной же статье хотелось бы рассмотреть её небольшую часть, а именно нечёткий поиск или Fuzzy Search для оценки похожести строк.
В целом нечёткий поиск может быть использован в разных сценариях, например:
- Для облегчения поиска пользователя, когда заранее может быть неизвестно точное наименование материала или номера документа.
- Для поиска по заранее определённым столбцам, когда пользователь ищет некоторый адрес вводя индекс или часть названия улицы.
- Для сопоставления распознанных данных в каком-нибудь OCR движке (который может иногда выдавать не 100% результат) с тем что лежит в системе.
В ABAP есть встроенный механизм позволяющий оценить похожесть двух строк — функция distance, которая работает на базе алгоритма подсчёта расстояния Левенштейна.
Функция возвращает количество операций удаления, вставки и изменения, необходимых для преобразования одной строки в другую. Однако данная функция в отличие от Fuzzy Search не обладает той же гибкостью.
Fuzzy Search в средствах поиска
Если Вы работаете в более менее современных системах на базе СУБД HANA, то наверное уже замечали встроенный механизм нечёткого поиска при вводе в средствах поиска, например поиск по имени класса:
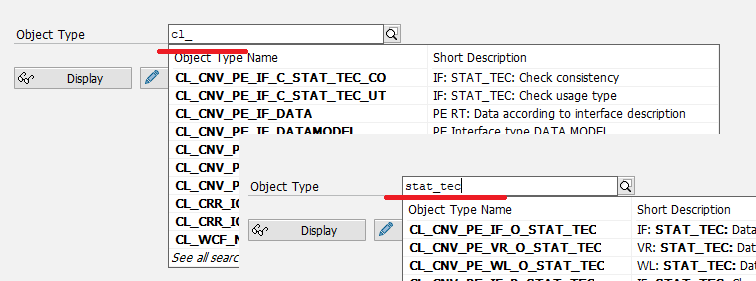
В соответствующем СП выставлены параметры нечёткого поиска:
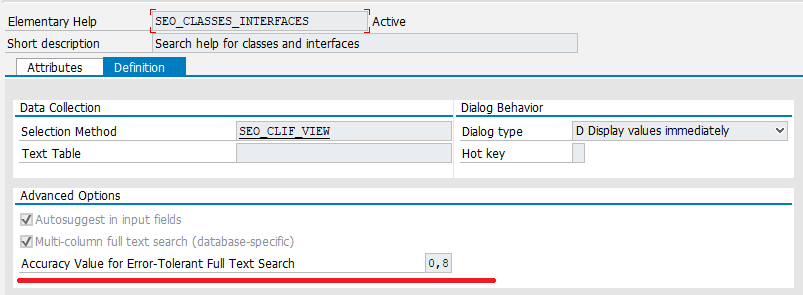
В интерфейсах вызова СП появились соответствующие опции:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
DATA: ls_shlp_descr TYPE shlp_descr, lv_rc LIKE sy-subrc, lt_values TYPE STANDARD TABLE OF ddshretval. PARAMETERS: p_req TYPE string. START-OF-SELECTION. CONSTANTS: lc_search_help TYPE shlpname VALUE 'SEO_CLASSES_INTERFACES'. CALL FUNCTION 'F4IF_GET_SHLP_DESCR' EXPORTING shlpname = lc_search_help shlptype = 'SH' IMPORTING shlp = ls_shlp_descr. ls_shlp_descr-textsearch-fields = VALUE ddsh_textsearch_fields( ( CONV #( 'NAME' ) ) ( CONV #( 'DESCRIPTION' ) ) ). ls_shlp_descr-textsearch-request = p_req. ls_shlp_descr-intdescr-fuzzy_search = abap_true. ls_shlp_descr-intdescr-fuzzy_similarity = '0.8'. CALL FUNCTION 'F4IF_SELECT_VALUES' EXPORTING shlp = ls_shlp_descr maxrows = 12 TABLES record_tab = lt_values. cl_demo_output=>display( lt_values ). |
Внутри вызывается движок SADL и преобразование к Native SQL следующего вида:
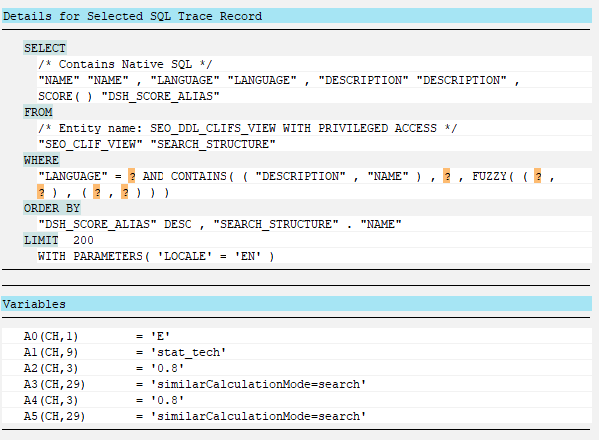
Обратите внимание на режим поиска: similarCalculationMode=search. Позже рассмотрим этот и другие режимы когда будем рассматривать сопоставления строк.
Синтаксис вызова Fuzzy Search в SQLScript
Упрощённый синтаксис вызова Fuzzy Search в SQLScript выглядит следующим образом:
|
1 2 3 4 |
SELECT SCORE() AS score, * FROM table_name WHERE CONTAINS(column_name, '123', FUZZY(0.8)) ORDER BY score DESC; |
В данном запросе мы найдём все строки в таблице table_name, где для поля column_name будут найдены значения, уровень похожести которых на «123» будет более 0.8.
- Уровень похожести определяется числом от 0 до 1, где 1 — полное соответствие.
- Значение 0.0 переданное в функцию FUZZY будет обозначать выборку всех значений > 0.
- Функция SCORE() выдаёт результат оценки похожести.
Функция CONTAINS может быть использована для разного рода поиска, но в данном случае используется именно нечёткий поиск — функция FUZZY.
Функция FUZZY можно настраивать через передачу параметров:
|
1 2 3 4 |
SELECT SCORE() AS score, * FROM table_name WHERE CONTAINS(column_name, 'Значение', FUZZY(0.8, 'option1=value1, option2=value2')) ORDER BY score DESC; |
Поиск может быть выполнен с учётом нескольких столбцов:
|
1 |
SELECT ... WHERE CONTAINS((col1, col2, col3), 'term1 term2 term3', FUZZY(0.7)) ...; |
Внутри функции CONTAINS можно использовать специальный синтаксис запросов включающий в себя зарезервированные слова и символы:
- CONTAINS(col, ‘sap OR hana’), где OR (чувствителен к регистру) обозначает ИЛИ, выбрать все значения где есть sap или hana.
- CONTAINS(col, ‘sap -hana’), выбрать все значения где есть sap, но не hana.
- CONTAINS(col, ‘»sap hana»‘), если брать в двойных кавычках поиск будет по фразе целиком.
- * (%) или ?, активируют поиск по шаблону, при этом нечёткий поиск выполняться не будет.
Следует учитывать что при передаче параметров в функцию FUZZY одновременно с вышеуказанными параметрами CONTAINS запрос разбивается на подзапросы:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
SELECT ... WHERE CONTAINS(col1, 'terma OR termb', FUZZY(0.7, 'opt1=val1, opt2=val2')) ...; /* будет преобразован в два подзапроса */ SELECT ... WHERE (CONTAINS(col1, 'terma', FUZZY(0.7, 'opt1=val1, opt2=val2')) OR CONTAINS(col1, 'termb', FUZZY(0.7, 'opt1=val1, opt2=val2'))) ...; SELECT ... WHERE CONTAINS(col1, 'this is a "search term"', FUZZY(0.7, 'opt1=val1, opt2=val2')) ...; /* Так же будет преобразован в несколько подзапросов */ SELECT ... WHERE (CONTAINS(col1, 'this is a', FUZZY(0.7, 'opt1=val1, opt2=val2')) AND CONTAINS(col1, '"search term"', FUZZY(0.7, 'opt1=val1, opt2=val2'))) ...; |
Аналогичное поведение будет при использовании поиска по нескольким столбцам:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
SELECT ... WHERE CONTAINS((col1, col2), 'terma termb', FUZZY((0.7, 'opt1=val1, opt2=val2'), (0.9, 'opt3=val3'))) ...; /* Будет выполнено несколько подзапросов */ SELECT ... WHERE ( CONTAINS(col1, 'terma', FUZZY(0.7, 'opt1=val1, opt2=val2')) AND CONTAINS(col1, 'termb', FUZZY(0.7, 'opt1=val1, opt2=val2')) ) OR ( CONTAINS(col1, 'terma', FUZZY(0.7, 'opt1=val1, opt2=val2')) AND CONTAINS(col2, 'termb', FUZZY((0.9, 'opt3=val3')) ) OR ( CONTAINS(col2, 'terma', FUZZY((0.9, 'opt3=val3')) AND CONTAINS(col1, 'termb', FUZZY(0.7, 'opt1=val1, opt2=val2')) ) OR ( CONTAINS(col2, 'terma', FUZZY((0.9, 'opt3=val3')) AND CONTAINS(col2, 'termb', FUZZY((0.9, 'opt3=val3')) ) OR CONTAINS(col1, '"terma termb"', FUZZY(0.7, 'opt1=val1, opt2=val2')) OR CONTAINS(col2, '"terma termb"', FUZZY((0.9, 'opt3=val3')) ...; |
Если внутри запроса используется поиск по нескольким полям, функция SCORE будет возвращать средневзвешенное значение по всем полям используемым в запросе:
|
1 2 3 4 5 |
SELECT SCORE(), col1, col2, ... FROM tab WHERE CONTAINS(col1, 'x y z') AND CONTAINS(col2, 'a b c') AND ... ORDER BY SCORE() DESC; |
Вес каждого поля по умолчанию равен 1 (т.е. при оценке они равны между собой), допускается ручное указание весов:
|
1 2 3 4 5 6 |
SELECT SCORE(), ... FROM tab WHERE CONTAINS((col1, col2, col3), 'a b c', FUZZY(0.8), WEIGHT(1.0, 0.5, 0.5)) AND CONTAINS(col4, 'x y z', FUZZY(0.7), WEIGHT(0.7)) AND CONTAINS(col5, 'u v w', FUZZY(0.7)) AND ... ORDER BY SCORE() DESC; |
Оценка похожести строк
С помощью опции similarCalculationMode мы можем определить то, каким образом будет оцениваться похожесть строк.
Похожесть строки А (строка поиска) по отношению к строке Б (строка в таблице) оценивается на основании следующих критериев:
- общие символы в А и Б
- дополнительные символы в строке А
- дополнительные символы в строке Б
- ошибочные символы (опечатки) в строке А
По своей сути допустимые для выставления режимы сопоставления отличаются влиянием вышеуказанных критериев на результат:
| Режим | Опечатки | Доп. символы в А | Доп. символы в Б |
|---|---|---|---|
| compare (по умолчанию) | среднее | высокое | высокое |
| search | высокое | высокое | низкое |
| searchCompare | среднее/высокое | высокое | низкое |
| symmetricsearch | высокое | среднее | среднее |
| substringsearch | высокое | высокое | низкое |
| typeAhead | высокое | очень высокое | низкое |
| flexible | управляется параметром errorDevaluate | очень высокое | управляется параметром lengthTolerance |
Рассмотрим на примерах:
| Строка А | Строка Б | compare | typeAhead | searchCompare |
|---|---|---|---|---|
| search | searching | 0.76 | 1.0 | 1.0 |
| search | seerch | 0.85 | 0.85 | 0.85 |
| search | searchingforextraterrestriallife | 0.0 | 0.91 | 0.91 |
| searchingforextraterrestriallife | searching | 0.0 | 0 | 0 |
| searchingforextraterrestriallife | seerch | 0.0 | 0 | 0 |
| searchingforextraterrestriallife | searchingforthemeaningoflife | 0.6 | 0.6 | 0.6 |
| Строка А | Строка Б | search | symmetric | substring |
|---|---|---|---|---|
| search | searching | 0.96 | 0.86 | 0.9 |
| search | seerch | 0.75 | 0.75 | 0.8 |
| search | searchingforextraterrestriallife | 0.91 | 0.87 | 0.88 |
| searchingforextraterrestriallife | searching | 0.35 | 0.84 | 0 |
| searchingforextraterrestriallife | seerch | 0.24 | 0.79 | 0 |
| searchingforextraterrestriallife | searchingforthemeaningoflife | 0.57 | 0.6 | 0 |
Более подробное пояснение по каждому из режимов можно найти в официальной документации.
Вызов из ABAP
Вызвать функционал сопоставления строк через Fuzzy Search можно в AMDP процедуре:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 |
CLASS zcl_hdb_string_comparator DEFINITION PUBLIC FINAL CREATE PUBLIC. PUBLIC SECTION. CONSTANTS: BEGIN OF gc_search_modes, compare TYPE string VALUE 'compare', search TYPE string VALUE 'search', searchcompare TYPE string VALUE 'searchCompare', symmetricsearch TYPE string VALUE 'symmetricsearch', substringsearch TYPE string VALUE 'substringsearch', typeahead TYPE string VALUE 'typeAhead', flexible TYPE string VALUE 'flexible', abap TYPE string VALUE 'ABAP', END OF gc_search_modes. TYPES: ty_score TYPE p LENGTH 3 DECIMALS 4, BEGIN OF ts_score, score TYPE ty_score, END OF ts_score, tt_scores TYPE STANDARD TABLE OF ts_score WITH DEFAULT KEY. INTERFACES: if_amdp_marker_hdb. CLASS-METHODS: match IMPORTING iv_sub TYPE string iv_val TYPE string iv_fuzzy_score TYPE ty_score OPTIONAL iv_search_mode TYPE string OPTIONAL iv_flex_conf TYPE string OPTIONAL EXPORTING ev_fact_score TYPE ty_score RETURNING VALUE(rv_score) TYPE ty_score. PRIVATE SECTION. CLASS-METHODS: match_int IMPORTING VALUE(iv_sub) TYPE string VALUE(iv_val) TYPE string VALUE(iv_search_mode) TYPE string VALUE(iv_fuzzy_score) TYPE ty_score EXPORTING VALUE(et_scores) TYPE tt_scores RAISING cx_amdp_error. ENDCLASS. CLASS zcl_hdb_string_comparator IMPLEMENTATION. METHOD match. DATA: lv_mode TYPE string. CLEAR ev_fact_score. IF iv_search_mode IS INITIAL. rv_score = ev_fact_score = COND #( WHEN iv_sub = iv_val THEN 1 ELSE 0 ). RETURN. ENDIF. IF iv_search_mode = gc_search_modes-abap. rv_score = ev_fact_score = ( 1 - distance( val1 = iv_sub val2 = iv_val ) / nmax( val1 = strlen( iv_sub ) val2 = strlen( iv_val ) ) ). ELSE. lv_mode = iv_search_mode. IF iv_flex_conf IS NOT INITIAL. lv_mode = lv_mode && `, ` && iv_flex_conf. ENDIF. TRY. match_int( EXPORTING iv_search_mode = lv_mode iv_val = iv_val iv_sub = iv_sub iv_fuzzy_score = 0 IMPORTING et_scores = DATA(lt_scores) ). rv_score = ev_fact_score = VALUE #( lt_scores[ 1 ]-score OPTIONAL ). CATCH cx_amdp_error. RETURN. ENDTRY. ENDIF. rv_score = COND #( WHEN rv_score >= iv_fuzzy_score THEN rv_score ELSE 0 ). ENDMETHOD. METHOD match_int BY DATABASE PROCEDURE FOR HDB LANGUAGE SQLSCRIPT OPTIONS READ-ONLY. DECLARE lt_search_tab TABLE ( col_search NVARCHAR(1000)); lt_search_tab[1] = :iv_val; et_scores = SELECT SCORE() AS score FROM :lt_search_tab WHERE CONTAINS( col_search, :iv_sub, FUZZY( :iv_fuzzy_score, :iv_search_mode ) ); ENDMETHOD. ENDCLASS. |
В классе можно воспользоваться как ABAP режимом сопоставления через функцию distance, так и прочими режимами рассмотренными ранее.
Программа для тестирования сопоставлений:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 |
PARAMETERS: p_1 TYPE text1024, p_2 TYPE text1024, p_m TYPE text1024 DEFAULT 'COMPARE', p_sc TYPE zcl_hdb_string_comparator=>ty_score DEFAULT '0.5', p_flex TYPE text1024. TYPES: BEGIN OF ts_modes, mode TYPE char100, END OF ts_modes, tt_modes TYPE STANDARD TABLE OF ts_modes WITH EMPTY KEY. DATA lt_return_table TYPE STANDARD TABLE OF ddshretval. AT SELECTION-SCREEN ON VALUE-REQUEST FOR p_m. DATA(lt_modes) = VALUE tt_modes( FOR <ls> IN CAST cl_abap_structdescr( CAST cl_abap_classdescr( cl_abap_classdescr=>describe_by_name( 'ZCL_HDB_STRING_COMPARATOR' ) )->get_attribute_type( 'GC_SEARCH_MODES' ) )->get_components( ) ( mode = <ls>-name ) ). CALL FUNCTION 'F4IF_INT_TABLE_VALUE_REQUEST' EXPORTING retfield = 'MODE' value_org = 'S' TABLES value_tab = lt_modes return_tab = lt_return_table. p_m = VALUE #( lt_return_table[ 1 ]-fieldval OPTIONAL ). START-OF-SELECTION. zcl_hdb_string_comparator=>match( EXPORTING iv_sub = CONV #( p_1 ) iv_val = CONV #( p_2 ) iv_fuzzy_score = p_sc iv_search_mode = CONV #( p_m ) iv_flex_conf = CONV #( p_flex ) RECEIVING rv_score = DATA(rv_score) ). WRITE: 'Оценка: ', rv_score. INITIALIZATION. %_p_1_%_app_%-text = 'Что ищем (строка А)'. %_p_2_%_app_%-text = 'Где ищем (строка Б)'. %_p_m_%_app_%-text = 'Режим сопоставления'. %_p_sc_%_app_%-text = 'Минимальный порог'. %_p_flex_%_app_%-text = 'Доп. параметры к гибкому режиму'. |
Спасибо.